






Streaming Wars: The Most Common Customer Pain Points
By Michaela VoglApr 11
Unlock the secrets to staying ahead in the ever-evolving world of social media marketing.
Published March 13th 2023
Read our 2024 Oscars blog here.
The 95th Academy Awards saw plenty of hype online. The event, hosted by Jimmy Kimmel, saw 1.4 million mentions online throughout the broadcast. That’s impressive.
This year’s Oscar awards celebrated the Indian documentary Elephant Whisperers winning Best Documentary Short Film, a huge seven wins for the film Everything Everywhere All At Once, and even some subtle nods towards last year’s Oscar drama.
Read on to discover the biggest moments and names that surfaced across Twitter conversations during the Oscars 2023.
Note on methodology: All the data mentioned here was gathered from 8 PM EST to roughly 11:40 PM EST on 12th March 2023 (the time frame of the Oscars 2023 event). All data comes from public Twitter mentions for each award category and associated nominees.
While the 95th Academy Awards saw incredible chatter online, it didn’t top last year’s mention numbers. 2022’s Oscars saw 1.8 million mentions, compared to this year’s 1.4 million. Plenty of these mentions can be chalked up to Will Smith’s altercation with Chris Rock – which sparked thousands of tweets during the broadcast last year. Without such drama this year, we expected mention numbers to be down.
That being said, those 1.4 million mentions have to count for something. So, what got people talking?
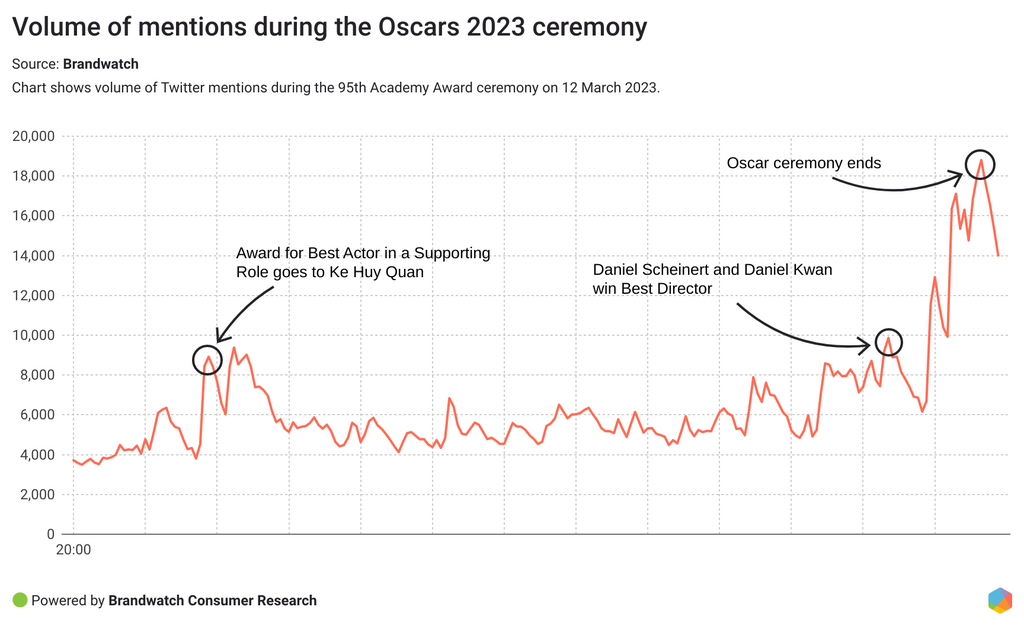
We used Brandwatch Consumer Research to look at minute-by-minute mentions of the Oscars.
The most discussed moment during the 2023 Oscar ceremony was the Best Director category announcement. Daniel Scheinert and Daniel Kwan won this award for their work on Everything Everywhere All At Once. In fact, this manic multiverse fantasy film won an impressive seven Oscars during the night, including best actress, best supporting actor, best editing, and best original screenplay. It was the most nominated film of the night.
Another key talking point of this year’s Oscars was the Indian documentary Elephant Whisperers winning Best Documentary Short Film. Fans were ecstatic to see that an Indian documentary had earned the win.
Jimmy Kimmel hosted this year’s Oscars for the third time, accumulating over 20k social media mentions during the ceremony.
Reviews of Kimmel’s hosting were mixed. A large portion of negative mentions surrounded Kimmel’s joke about Will Smith slapping Chris Rock at last year’s ceremony. Some users thought Kimmel's jokes weren’t funny – which is always a criticism for such hosts – and some thought he should focus on new material, instead of dwelling on Will Smith. When analyzing the attitude towards Kimmel's performance, 61% of sentiment-categorized mentions were negative.
Yet, Kimmel also saw thousands of positive comments praising his hosting skills. Many hailed the host's impressive parachute entrance as 'grand.' His opening monologue was also commended on social, with users saying he was the perfect host for the Oscars – and that the Oscars felt safer in his hands.
Commentators echoed this view, saying Kimmel's monologue was a love fest – despite a few light jabs. Several comments also reflected on Kimmel's tone, stating how happy he looked presenting.
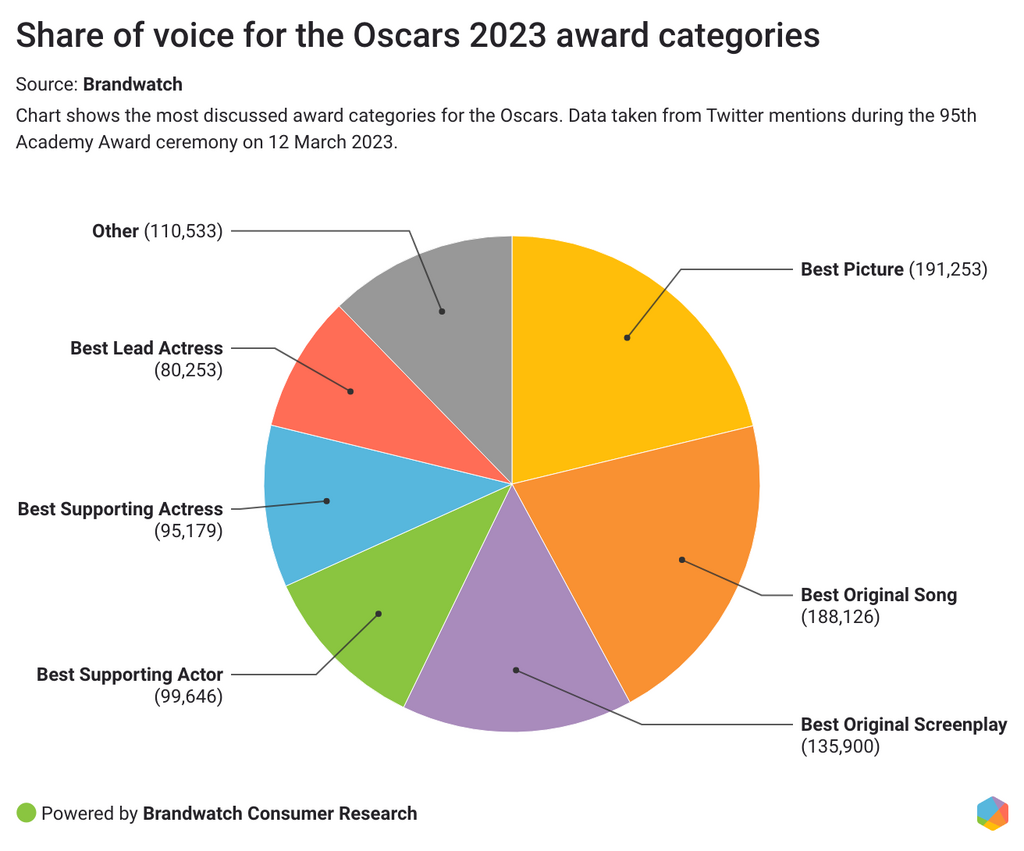
The Best Picture category was highly commended on social media. There were over 190k mentions of Best Picture on Twitter during the ceremony, as users celebrated Everything Everywhere All At Once taking home the award. It was the most discussed category of the ceremony. The film also won Best Original Screenplay, a category that saw over 136k mentions online.
The Best Original Song category saw more than 188k mentions on social, making it the second most discussed award category of the night. The song Naatu Naatu from the hit Telugu-language film RRR made history by becoming the first Indian film song to win an Oscar. The track beat the likes of Lady Gaga and Rihanna who were also nominated for the title – and fans were exceptionally vocal about the win on social.
When diving into individual categories, Ke Huy Quan dominated almost all mentions for Best Supporting Actor – accounting for 97% of nominee mentions. The actor’s performance in Everything Everywhere All At Once earned him the win for this category – and fans praised the performance on social.
For Best Supporting Actress, views were mixed. Angela Bassett accounted for more than 51% of mentions while winner Jamie Lee Curtis accounted for just 34%. The win was not well received by most social media users. According to the online commentary, the majority of users thought nominees Angela Bassett or Stephanie Hsu deserved to take home the award. Several users also expressed disappointment with the Oscars for rewarding careers over acting performances.
From fans celebrating Everything Everywhere All At Once’s impressive seven wins, to users sharing praise for Indian documentaries and songs stealing the show, this year’s Oscars saw plenty of buzz online.
Although the infamous slap from 2022’s Oscars contributed an extra few hundred thousand mentions towards last year’s event, 2023’s awards still saw millions of Twitter users getting involved online – without the drama.
It’s safe to say the Academy Awards is an event to watch.
Offering up analysis and data on everything from the events of the day to the latest consumer trends. Subscribe to keep your finger on the world’s pulse.
Consumer Research gives you access to deep consumer insights from 100 million online sources and over 1.4 trillion posts.
Existing customer?Log in to access your existing Falcon products and data via the login menu on the top right of the page.New customer?You'll find the former Falcon products under 'Social Media Management' if you go to 'Our Suite' in the navigation.
Brandwatch acquired Paladin in March 2022. It's now called Influence, which is part of Brandwatch's Social Media Management solution.Want to access your Paladin account?Use the login menu at the top right corner.