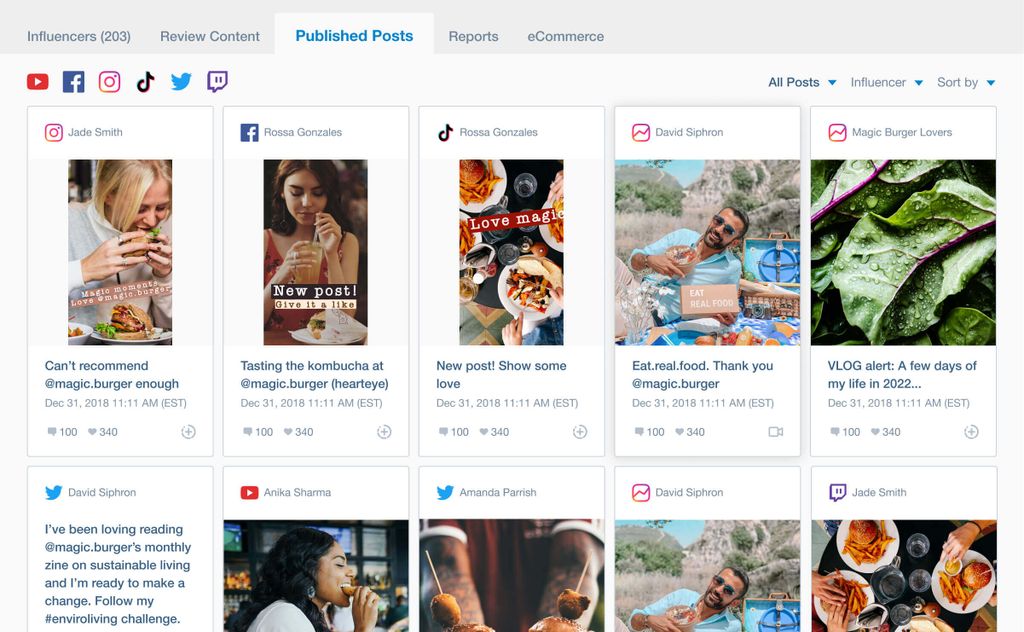
Audience relevance
An influencer's audience matters more than the influencer themselves. A beauty creator with 2 million followers won't help your B2B SaaS company, no matter how impressive their reach looks.
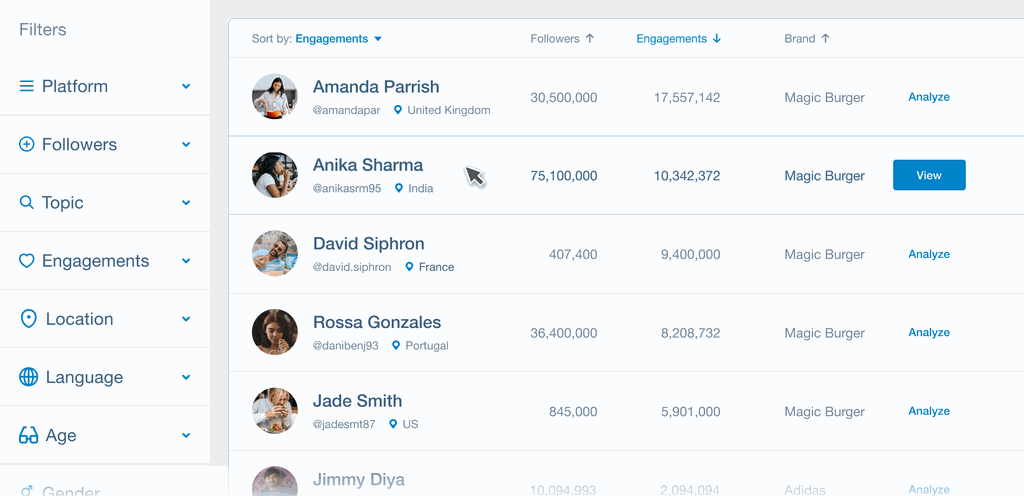
Dig into demographics. What's the age range, geographic location, and gender split of their audience? Do their followers' interests align with your product or service? Brandwatch Influence lets you filter creators by audience demographics, interests, and behaviors, ensuring you find influencers whose followers match your target customers.
Look for overlap between the creator's audience and your ideal customer profile. The more alignment, the better your campaign will perform.
Authentic engagement
Engagement rate is the percentage of an influencer's followers who interact with their content through likes, comments, shares, and saves. It's a much better indicator of influence than follower count.
Calculate engagement rate by dividing total engagement (likes + comments + shares) by follower count, then multiply by 100. Anything above 3-5% is generally considered strong, though this varies by platform and audience size.
Watch out for signs of inauthentic engagement. Generic comments ("Great post!" or "Love this!" repeated across multiple posts), sudden follower spikes, or engagement that doesn't match content quality can indicate purchased followers or engagement pods.
Look for genuine conversations in the comments. Are people asking questions, sharing personal stories, or engaging in meaningful dialogue? That's authentic influence at work.
Using Brandwatch Influence you can generate a report about an influencer to analyze the health of their social accounts, including the quality of their audience.
Brand fit and content style
An influencer's aesthetic, tone, and content style should complement your brand identity. A creator known for edgy humor might not align with a luxury brand's refined image, even if their audience demographics match perfectly.
Review their recent content. Does their visual style, voice, and messaging feel like a natural fit for your brand? Could you imagine your product or service appearing in their feed without feeling forced?
Also consider past brand partnerships. Have they worked with competitors? How did they integrate sponsored content? Creators who've demonstrated skill at blending brand partnerships with their organic content are more likely to create authentic campaigns for you.
Brand Affinity within Brandwatch Influence helps you determine whether an influencer is the right fit for your brand based on which topics and themes their audience tends to engage with. Check whether they have engaged with similar brands in the past to gauge whether your campaign is likely to succeed with them.
Credibility and trust
Influencers earn their influence through credibility. Their audience trusts them because they've demonstrated expertise, consistency, and authenticity over time.
Look for creators who show deep knowledge in their niche. Do they educate their audience? Do they share personal experiences and honest opinions? Are they consistent in their messaging and values?
Community trust shows up in how audiences respond. Read the comments. Do people thank the creator for recommendations? Do they share their own experiences or ask follow-up questions? That level of engagement signals genuine trust.